Projects
A selection of projects focused on product analytics, applied machine learning, and decision-support systems.
I Help Businesses
What I Do
I work at the intersection of data and product, helping teams define metrics, explore data, and translate insights into decisions that shape product direction.
1. Product Analytics & Growth
Designed a product analytics framework (event taxonomy, funnel KPIs, dashboards) to track user engagement and support growth decisions in an early-stage startup environment. Defined activation and conversion metrics, enabling structured analysis of user behavior and clearer prioritization of growth initiatives. Focus: product metrics, funnel analysis, decision support
2. AI Systems for Business Impact
Designed a multi-agent AI system to transform unstructured educational data into structured, decision-ready outputs. Built a RAG-based pipeline for curriculum alignment and insight generation, with a focus on interpretability and real-world usability. Focus: applied AI systems, data pipelines, decision support
3. Lead Conversion & Growth
Analyzed multi-year marketing and referral data to identify drivers of lead conversion. Translated analytical outputs into operational recommendations (e.g., response time improvements, consultation flow changes) to improve conversion outcomes. Focus: business impact, feature engineering, stakeholder translation
4. Computer vision & OCR
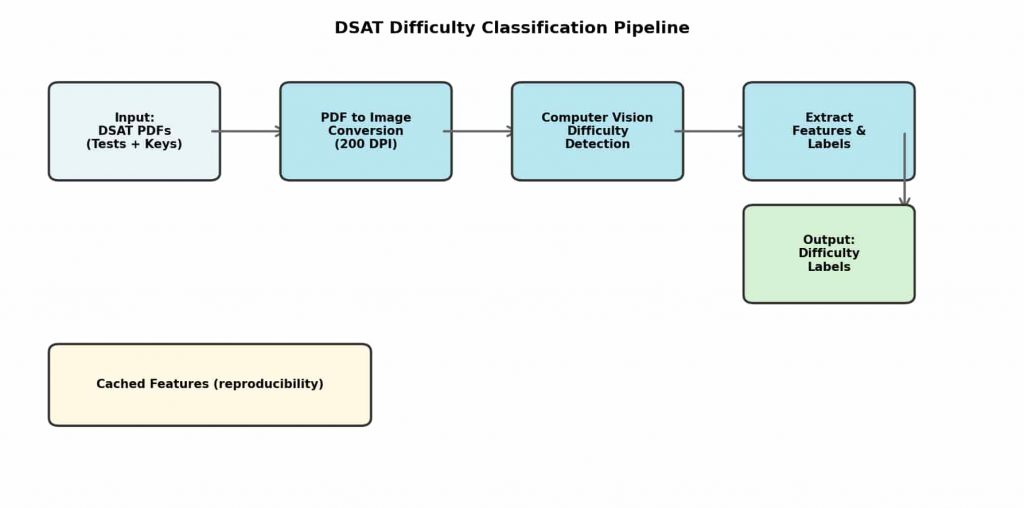
An end-to-end computer vision pipeline that classifies Digital SAT questions by difficulty at 98–99% accuracy, making consistent, scalable instructional planning possible without touching question text.
Problem
Test prep instructors manually categorized hundreds of Digital SAT questions by difficulty for every practice test; a slow, inconsistent process that bottlenecked curriculum planning and introduced rater bias. With 6 official practice papers and ~90 pages each, this was unsustainable at scale.
Approach
Built an end-to-end pipeline processing 588 question pages extracted from official College Board practice tests. The system converts PDF answer keys to high-resolution grayscale images, isolates the difficulty marker region using calibrated coordinates, and applies binary thresholding with contour detection to count filled circles, mapping 3+ circles to Hard, 2 to Medium, 1 to Easy.
No text parsing, no NLP. The entire classification relies on visual structure.
Insight
The College Board encodes difficulty as a visual pattern, filled circle count, in its answer keys. Once the right image region is isolated, this signal can be extracted programmatically with high reliability across all official test formats, making the approach robust and reusable.
Impact
The pipeline processed ~540 questions across 6 practice tests, achieving 98–99% classification accuracy. Manual labeling time dropped from approximately 2 hours to under 5 minutes per test. The project also demonstrates IP-compliant data science: the repo ships with cached derived features rather than copyrighted source materials, making it fully shareable and reproducible.
Python · OpenCV · OCR · pdf2image · Computer Vision · Jupyter · Reproducible Pipelines
5. Unsupervised ML & Equity Analytics
K-Means clustering and a fairness audit revealed that financial burden, not academic preparation, is the primary driver of dropout risk, pointing to where targeted interventions will have the most impact.
Problem
Educational institutions often have aggregate outcome data (graduation rates, GPA distributions), but lack visibility into the distinct pathways students take to reach those outcomes. Without segmentation, it’s impossible to identify at-risk groups early enough to intervene, or to design supports that target the right students.
Approach
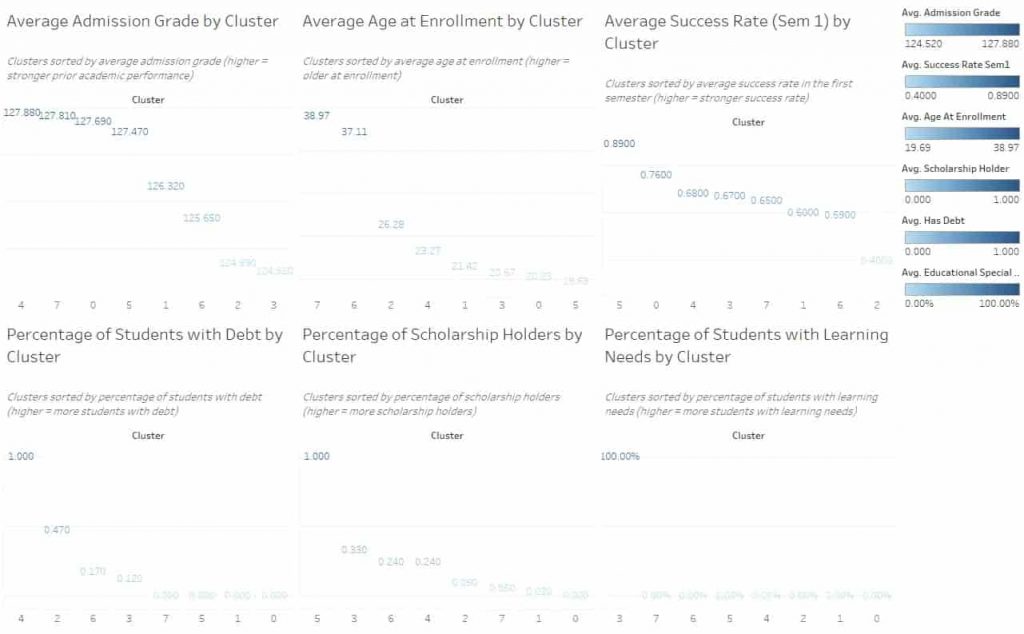
Applied K-Means clustering (k=8, selected via elbow method, Davies-Bouldin index, and interpretability triangulation) to a 4,424-student higher education dataset with 36 variables spanning academic performance, demographics, and financial indicators. Used UMAP for 2D cluster visualization and ran chi-square fairness audits on sensitive attributes (gender and age) to identify demographic skews before recommending any intervention.
Insight
Financial burden and age, not academic preparedness, are the strongest differentiators between student success and dropout. Scholarship support emerged as the clearest protective factor across all clusters.
For example, cluster 1 had a 40% dropout risk and comprised older learners carrying debt. In contrast, cluster 4 had a 89% success rate and encompassed younger students with scholarships.
Impact
Delivered 8 cluster profiles and a Tableau dashboard designed for non-technical stakeholders, translating ML outputs into actionable intervention recommendations. The fairness audit framework demonstrates how to surface demographic skews before deploying any support program, reducing the risk of interventions that help some groups while inadvertently overlooking others.
Python · scikit-learn · K-Means · UMAP · Tableau · Chi-Square Testing · Equity Analysis · Jupyter
6. SQL & Database Design
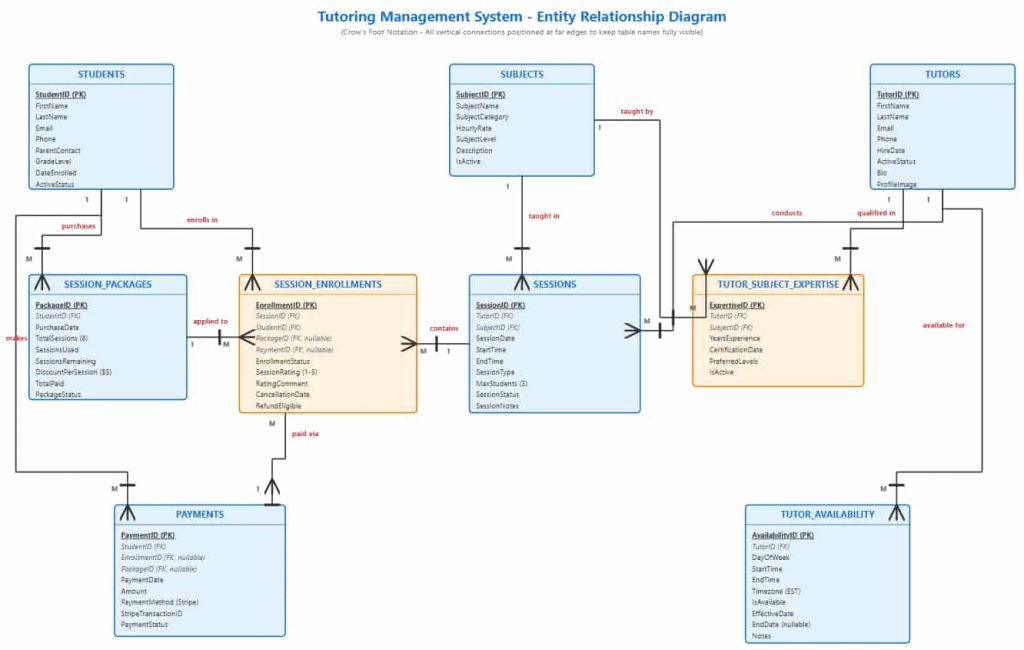
A 9-table normalized MySQL schema, covering students, tutors, sessions, packages, and payments, that answers three critical business questions in real time: what generates revenue, who is available, and which packages are going unused.
Problem
A tutoring business managing group sessions, prepaid packages, multi-subject tutors, and Stripe payments cannot scale on spreadsheets. Without a reliable data model, three questions that directly affect revenue go unanswered: which subjects generate the most income, which tutors are available and qualified for a specific student request, and which prepaid packages are expiring with sessions still unused.
Approach
Designed a fully normalized (3NF) relational schema in MySQL 8.0 with 9 interconnected tables: Students, Tutors, Subjects, Sessions, Session_Packages, Payments, Session_Enrollments, Tutor_Subject_Expertise, and Tutor_Availability. Applied Crow’s Foot ER modeling, composite indexing, and business-rule constraints, including group session size limits, a 24-hour cancellation policy, Stripe transaction ID tracking, and a generated column for package session credits that eliminates update anomalies.
Three analytical queries were written to directly answer three business questions.
Insight
Math/Science sessions generated 53% of total revenue. A single 5-table JOIN identifies the specific tutor(s) qualified, rated highly, and available. Sorting active packages by sessions remaining identifies exactly which students need a renewal reminder.
Impact
Delivered an analytics-ready schema with enforced business rules that makes reliable operational reporting possible. This project demonstrates the ability to design the data infrastructure that makes dashboards and models trustworthy in the first place.
SQL · MySQL 8.0 · Database Design · ER Modeling · 3NF Normalization · Analytical Queries